

In 2019, some 10 million developers joined Github and contributed over 44 million repositories in that year alone. Github is the most popular code repository, with 80% of its users located outside of the U.S. The open source platform is not used only by experienced software developers. Last year, there were over 760,000 developers using it for learning purposes, and nearly 20,000 high schools, universities, and bootcamps around the world were using it in their projects.
Actively used by large teams to be more efficient, Github leaves some room for errors which can end up leaking company secrets. Aware that at any given moment hard-coded credentials such as passwords, API keys, and OAuth tokens, as well as other critical technical information could be leaked online, security teams have been looking into different ways of scanning all public repositories. Indeed, secrets can leak from a company account, or from a developer’s personal account. Your company should therefore monitor not just their own repositories, but all of those that are public.
While you can’t control human errors in your team or the pressure that comes with short release cycles, you can definitely reduce the impact by achieving a higher detection rate with a tool that can cut through the noise, prioritize, and contextualize notifications.
Companies can choose between two different methods to detect technical leakage: in-house developed tools with manual checking or commercially available systems. Github, for instance, also comes with a scanning feature of public and private repositories to detect accidentally committed secrets.
Large companies have developed in-house tools to look for committed secrets in various source code repositories, but the high number of false positives makes it hard to identify a real secret from random strings that could come up. A major problem with in-house scanning tools is their high false positive rate which makes the investigation outcome unreliable.
Why reducing false positive rate is a hard problem
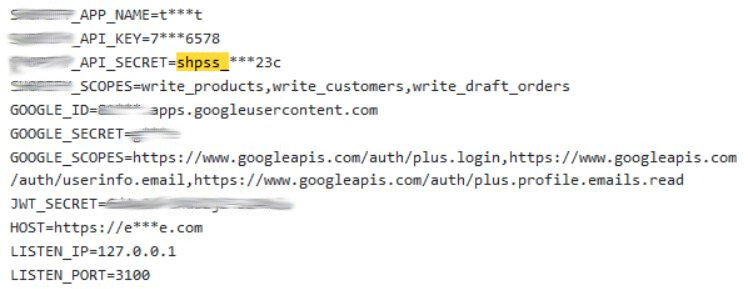
Below is a great example of a false positive for an ecommerce platform that always starts its secret keys with the same series of letters, in this case, “shpss”. In the image, we notice that a source code repository on Github included this string, but it was not a leak; it was merely part of a random string.

A better pattern to look for would actually be “shpss_” as the secret keys always include an underscore. The image below, however, shows another repository on Github which published that string, but did not leak any secrets either. The mix of stars and characters would make this code highly likely to generate a false positive.
In the image below, the source code repository has leaked a secret, as “shpss_” is followed by a long string of random characters. This leak is even more worrying as the administrator account of the developer’s database is publishing alongside the ecommerce access key.

These examples demonstrate how complicated it can be to automate the detection of false positives. What increases the level of this challenge is the fact that a company may need to monitor tens, if not hundreds of types of secrets, each with its own variations. The possibilities to account for quickly exceed any organization’s capabilities.
Developing smarter solutions
Using intelligent machine learning algorithms is a solution that automatically tells the difference between a genuine leaked secret and a false positive. Free and open source repository scanners are often python scripts that scrutinize the commit history of a code source repository to detect leaked credentials. There are a number of readily available tools that can validate data and display higher efficiency than in-house tools.
A dedicated commercial solution may combine a number of tactics to filter out the false positives that waste your company’s resources, and slow down your response time:
-
- Regular expressions that look for patterns rather than specific keywords. These are the equivalent of searching for a letter followed by a number followed by a letter, an optional space, and then the same pattern again, instead of a ZIP code such as H0H 0H0.
- Entropy queries that look for random strings of numbers, letters, and special characters. Since access keys are always randomly generated, they should in theory stand out from source code that uses function names.
- Machine learning algorithms that learn over time what a secret looks like, and seeks to find similar results in your source code repositories.
- Authenticated searches so that both public and private repositories are scanned in real-time to provide you with actionable intelligence to act fast.
Obviously, a commercial solution has a larger model and uses a wider variety of training data to improve detection and cut through all the false positives. While it’s true that no solution is perfect and there may still be some false positives lurking around, the rate of false positives in commercial solutions are lower than that of in-house tools.
A problem that is here to stay
Company secrets leaked in source code repositories are a serious issue because they are widely accessible. This means that they could also be easily copied or manipulated by malicious actors. We have previously explored their impact here, and have explained how criminals have used API keys to manipulate cloud resources for crypto mining. On any given day, our very own Firework solution detects an average of 2,500 secrets leaks. With the right tools, it is possible for your company not only to eliminate the false positives, but also to be made aware of leaks before malicious actors, thereby preventing any damage to your company and your brand.
David Hétu, PhD contributed to this article

